SETI@home: An Experiment in Public-Resource Computing
David P. Anderson
Jeff Cobb
Eric Korpela
Matt Lebofsky
Dan Werthimer
Space Sciences Laboratory
U.C. Berkeley
| ABSTRACT |
| SETI@home uses computers in homes and offices around the world to analyze radio telescope signals. This approach, though it presents some difficulties, has provided unprecedented computing power and has led to a unique public involvement in science. We describe SETI@home's design and implementation, and discuss its relevance to future distributed systems. |
SETI (Search for Extraterrestrial Intelligence) is a scientific area whose goal is to detect intelligent life outside Earth [SHO98]. One approach, known as radio SETI, uses radio telescopes to listen for narrow-bandwidth radio signals from space. Such signals are not known to occur naturally, so a detection would provide evidence of extraterrestrial technology [COC59].
Radio telescope signals consist primarily of noise (from celestial sources and the receiver's electronics) and man-made signals such as TV stations, radar, and satellites. Modern radio SETI projects analyze the data digitally. This analysis generally involves three phases:
- Compute the data's time-varying power spectrum.
- Find candidate signals using pattern recognition on the power spectra.
- Eliminate candidate signals that are probably natural or man-made.
More computing power enables searches to cover greater frequency ranges with more sensitivity. Radio SETI, therefore, has an insatiable appetite for computing power.
Previous radio SETI projects have used special-purpose supercomputers, located at the telescope, to do the bulk of the data analysis. In 1995, David Gedye proposed doing radio SETI using a virtual supercomputer composed of large numbers of Internet-connected computers, and he organized the SETI@home project to explore this idea. SETI@home has not found signs of extraterrestrial life. But, together with related distributed computing and storage projects, it has succeeded in establishing the viability of public-resource computing (so-called because the computing resources are provided by the general public).
Public-resource computing is neither a panacea nor a free lunch. For many tasks, huge computing power implies huge network bandwidth, and bandwidth is typically expensive or limited. This factor limited the frequency range searched by SETI@home, since greater range implies more bits per second. Compared to other radio SETI projects, SETI@home covers a narrower frequency range but does a more thorough search in that range (see Table 1).
| Project name | Sensitivity (Watts per square meter) | Sky coverage (% of sky) |
Frequency coverage (MHz) | Maximum signal drift rate (Hz/sec) | Frequency resolution (Hz) | Computing power (GFLOPS) |
|---|---|---|---|---|---|---|
| Phoenix | 1e-26 | 0.005 (1000 nearby stars) | 2000 | 1 | 1 | 200 |
| SETI@home | 3e-25 | 33 | 2.5 | 50 | 0.07 to 1200 (15 octaves) | 27,000 |
| SERENDIP | 1e-24 | 33 | 100 | 0.4 | 0.6 | 150 |
| Beta | 2e-23 | 70 | 320 | 0.25 | 0.5 | 25 |
The first challenge for SETI@home was to find a good radio telescope. The ideal choice was the telescope in Arecibo, Puerto Rico, the world's largest and most sensitive radio telescope. Arecibo is used for various astronomical and atmospheric research, and we could not obtain its long-term exclusive use. However, in 1997 the U.C. Berkeley SERENDIP project developed a technique for piggybacking a secondary antenna at Arecibo [WER97]. As the main antenna tracks a fixed point in the sky (under the control of other researchers), the secondary antenna traverses an arc that eventually covers the entire band of sky visible to the telescope. This data source can be used for a sky survey that covers billions of stars.
We arranged for SETI@home to share SERENDIP's data source. Unlike SERENDIP, we needed to distribute data through the Internet. At that time, Arecibo's Internet connection was a 56 Kbps modem, so we decided to record data on removable tapes (35GB DLT cartridges, the largest available at the time), have them mailed from Arecibo to our lab at U.C. Berkeley, and distribute data from servers there.
We decided to record data at 5 Mbps. This rate was low enough that the recording time per tape would be a manageable 16 hours, and it would be feasible to distribute the data through our lab's 100 Mbps Internet connection. But it was high enough to do significant science. With 1-bit complex sampling this rate yields a frequency band of 2.5 MHz - enough to handle Doppler shifts for relative velocities up to 260 km/sec, or about the galactic rotation rate (radio signals are Doppler shifted in proportion to the sender's velocity relative to the receiver). Like many other radio SETI projects, we centered our band at the Hydrogen line (1.42 GHz), within a frequency range where man-made transmissions are prohibited by an international treaty.
SETI@home's computational model is simple. The signal data is divided into fixed-size work units that are distributed, via the Internet, to a client program running on numerous computers. The client program computes a result (a set of candidate signals), returns it to the server, and gets another work unit. There is no communication between clients.
SETI@home does redundant computation: each work unit is processed multiple times. This lets us detect and discard results from faulty processors and from malicious users. A redundancy level of two to three is adequate for this purpose. We generate work units at a bounded rate and never turn away a client asking for work, so the redundancy level increases with the number of clients and their average speed. These quantities have increased greatly during the life of the project. We have kept the redundancy level within the desired range by revising the client to do more computation per work unit.
The task of creating and distributing work units is done by a server complex located in our lab (see Figure 1). Our reasons for centralizing the server functions were largely pragmatic: for example, tape handling is minimized.

Figure 1: The distribution of data.
Work units are formed by dividing the 2.5 MHz signal into 256 frequency bands, each about 10 KHz wide. Each band is then divided into 107-second segments, overlapped in time by 20 seconds. This ensures that signals we're looking for (which last up to 20 seconds; see below) are contained entirely in at least one work unit. The resulting work units are 350 KB - enough data to keep a typical computer busy for about a day, but small enough to download over a slow modem in a few minutes.
We use a relational database to store information about tapes, workunits, results, users, and other aspects of the project. We developed a multithreaded data/result server to distribute work units to clients. It uses an HTTP-based protocol so that clients inside firewalls can contact it. Work units are sent in least-recently-sent order.
A garbage collector program removes work units from disk, clearing an on-disk flag in their database records. We have experimented with two policies:
- Delete work units for which N results has been received, where N is our target redundancy level. If work unit storage fills up, work unit production is blocked and system throughput declines.
- Delete work units that have been sent M times, where M is slightly more than N. This eliminates the above bottleneck, but causes some work units never to have results. This fraction can be made arbitrarily small by increasing M. We are currently using this policy.
Keeping the server system running has been the most difficult and expensive part of SETI@home. The sources of failure, both hardware and software, have seemed limitless. We have converged to an architecture that minimizes dependencies between server subsystems. For example, the data/result server can be run in a mode where, instead of using the database to enumerate work units to send, it gets this information from a disk file. This lets us distribute data even when the database is down.
The client program repeatedly gets a work unit from the data/result server, analyzes it, and returns the result (a list of candidate signals) to the server. It needs an Internet connection only while communicating with the server. The client can be configured to compute only when its host is idle, or to compute constantly at a low priority. The program periodically writes its state to a disk file, and reads this file on startup; hence it makes progress even if the host is frequently turned off.
Analyzing a work unit involves computing signal power as a function of frequency and time, then looking for several types of patterns in this power function: spikes (short bursts), Gaussians (narrow-bandwidth signals with a 20-second Gaussian envelope, corresponding to the telescope's beam movement across a point), pulsed signals (Gaussian signals pulsed with arbitrary period, phase, and duty cycle), and triplets (three equally-spaced spikes at the same frequency; a simple pulsed signal). Signals whose power and goodness-of-fit exceed thresholds are recorded in the output file.
Outer loops vary two parameters [KOR01]:
- Doppler drift rate. If the sender of a fixed-frequency signal is accelerated relative to the receiver (e.g. by planetary motion) then the received signal drifts in frequency. Such signals can best be detected by undoing the drift in the original data, then looking for constant-frequency signals. The drift rate is unknown; we check 31,555 different drift rates, covering the range of physically likely accelerations.
- Frequency resolution. We cover 15 frequency resolutions ranging from 0.075 to 1220.7 Hz. This increases sensitivity to modulated signals, whose frequency content is spread over a range.
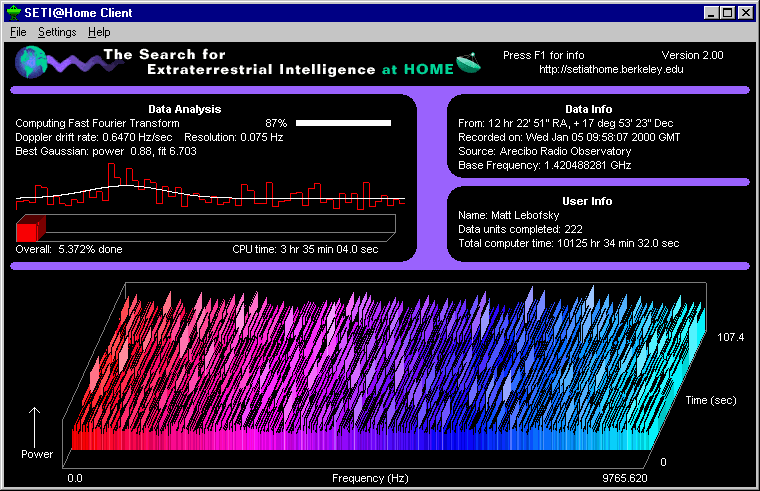
Figure 2: The SETI@home display, showing the power spectrum currently being computed (bottom) and the best-fit Gaussian (left).
The SETI@home client program is written in C++. The code consists of a platform-independent framework for distributed computing (6,423 lines), components with platform-specific implementations, such as the graphics library (2,058 lines in the UNIX version), SETI-specific data analysis code (6,572 lines), and SETI-specific graphics code (2,247 lines).
The client has been ported to 175 different platforms. The GNU tools, including gcc and autoconf, have greatly facilitated this task. We maintain the Windows, Macintosh, and SPARC/Solaris versions ourselves; all other porting is done by volunteers.
The client can run as a background process, as a GUI application, or as a screensaver. To support these different modes on multiple platforms, we use an architecture in which one thread does communication and data processing, a second thread handles GUI interactions, and a third thread (perhaps in a separate address space) renders graphics based on a shared-memory data structure.
Results are returned to the SETI@home server complex, where they are recorded and analyzed (see Figure 3).
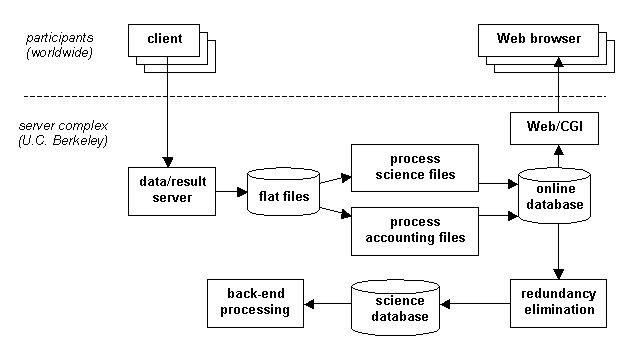
Figure 3: The collection and analysis of results.
Handling a result consists of two tasks:
- Scientific: The data/server writes the result to a disk file. A program reads these files, creating result and signal records in the database. To optimize throughput, several copies of this program run concurrently.
- Accounting: For each result, the server writes a log entry describing the result's user, its CPU time, and so on. A program reads these log files, accumulating in a memory cache the updates to all relevant database records (user, team, country, CPU type, and so on). Every few minutes it flushes this cache to the database.
By buffering updates in disk files, the server system can handle periods of database outage and overload.
Eventually, each work unit has a number of results in the database. A redundancy elimination program examines each group of redundant results - which may differ in number of signals and signal parameters - and uses an approximate consensus policy to choose a "canonical" result for that work unit. Canonical results are copied to a separate database.
The final phase, back-end processing, consists of several steps. To verify the system, we check for the test signals injected at the telescope. Man-made signals (RFI) are identified and eliminated. We look for signals with similar frequency and sky coordinates detected at different times. These "repeat signals", as well as one-time signals of sufficient merit, are investigated further, potentially leading to a final cross-check by other radio SETI projects according to an accepted protocol [DOP90].
The public response to SETI@home
We announced plans for SETI@home in 1998, and 400,000 people pre-registered during the next year. In May 1999 we released the Windows and Macintosh versions of the client. Within a week about 200,000 people had downloaded and run the client, and this number has grown to over 3.83 million as of July 2002. People in 226 countries run SETI@home; about half are in the U.S.
In the 12 months starting in July 2001 SETI@home participants processed 221 million work units. The average throughput during that period was 27.36 TeraFLOPS. Overall, the computation has performed 1.7e21 floating point operations, the largest computation on record.
SETI@home relies primarily on mass-media news coverage and word-of-mouth to attract participants. Our web site (http://setiathome.berkeley.edu) explains the project, lets users download the client program, and provides scientific and technical news.
The web site shows leader boards (based on work units processed) for individuals and for groupings such as countries and email domains. Users can form teams that compete within categories; 97,000 such teams exist. Leader-board competition (between individuals, teams, owners of different computer types, and so on) has helped attract and retain participants. In addition, users are recognized on the web site and thanked by email when they pass work unit milestones.
We have tried to foster a SETI@home community in which users can exchange information and opinions. The web site lets users submit profiles and pictures of themselves, and has an online poll with questions concerning demographics, SETI, and distributed computing (of the 95,000 users who have completed this poll, for example, 93% are male). We assisted in the creation of a newsgroup, sci.astro.seti, devoted largely to SETI@home. Users have created various ancillary software, such as proxy data servers and systems for graphically displaying work progress. Our web site contains links to these contributions. Users have translated the web site into 30 languages.
We have worked to prevent our client program from acting as a vector for software viruses, and thus far we have succeeded: our code download server has not (as far as we know) been penetrated, and the client program does not download or install code. There have been two noteworthy attacks. Our web server was compromised, but only as a prank; the hackers did not, for example, install a Trojan-horse download page. Later, exploiting a design flaw in our client/server protocol, hackers obtained some user email addresses. We fixed the flaw, but not until thousands of addresses had been stolen. In addition, a user developed an email-propagated virus that downloads and installs SETI@home on the infected computer, configuring it to give credit to his SETI@home account. This might have been prevented by requiring a manual step in the install process.
Conversely, we have had to protect SETI@home from misbehaving and malicious participants. There have been many instances of this, although only a tiny fraction of participants are involved. A relatively benign example: some users modified the client executable to improve its performance on specific processors. We didn't trust the correctness of such modifications, and we didn't want SETI@home to be used in "benchmark wars", so we adopted a policy banning modifications.
We have discovered and defeated many schemes for getting undeserved work credit. Other users deliberately sent erroneous results. These activities are hard to prevent if users can run the client program under a debugger, analyze its logic, and obtain embedded encryption keys [MOL00]. Our redundancy-checking, together with the error-tolerance of our computing task, are sufficient for dealing with the problem; other mechanisms have been proposed [SAR01]. Conclusions
Public-resource computing relies on personal computers with excess capacity, such as idle CPU time. The idea of using these cycles for distributed computing was proposed by the Worm computation project at Xerox PARC, which used workstations within a research lab [SHO82], and was later explored by academic projects such as Condor.
Large-scale public-resource computing became feasible with the growth of the Internet in the 1990s. Two major public-resource projects predate SETI@home. The Great Internet Mersenne Prime Search (GIMPS), which searches for prime numbers, started in 1996. Distributed.net, which demonstrates brute-force decryption, started in 1997. More recent applications include protein folding (folding@home) and drug discovery (the Intel-United Devices Cancer Research Project).
Several efforts are underway to develop general-purpose frameworks for public-resource and other large-scale distributed computing. Projects collectively called The Grid are developing systems for resource-sharing between academic and research organizations [FOS99]. Private companies such as Platform Computing, Entropia and United Devices are developing systems for distributed computation and storage in both public and organizational settings.
On a more general level, public-resource computing is an aspect of the "peer-to-peer paradigm", which involves shifting resource-intensive functions from central servers to workstations and home PCs [ORA01].
What tasks are amenable to public-resource computing? There are several factors. First, the task should have a high computing-to-data ratio. Each SETI@home data unit takes 3.9 trillion floating-point operations, or about 10 hours on a 500 MHz Pentium II, yet involves only a 350KB download and a 1 KB upload. This high ratio keeps server network traffic at a manageable level, and imposes minimal load on client networks. Applications such as computer graphics rendering require large amounts of data per unit computation, perhaps making them unsuitable to public-resource computation. However, reductions in bandwidth costs will allay these problems, and multicast techniques can reduce cost when a large part of the data is constant across work units.
Secondly, tasks with independent parallelism are easier to handle. SETI@home work unit computations are independent, so participant computers never have to wait for or communicate with one another. If a computer fails while processing a work unit, the work unit is eventually sent to another computer. Applications that require frequent synchronization and communication between nodes have been parallelized using hardware-based approaches such as shared-memory multiprocessors, and more recently via software-based cluster computing, such as PVM [SUN90]. Public-resource computing, with its frequent computer outages and network disconnections, seems ill-suited to these applications. However, scheduling mechanisms that find and exploit groups of LAN-connected machines may eliminate these difficulties.
Thirdly, tasks that tolerate errors are more amenable to public-resource computing. For example, if a SETI@home work unit is analyzed incorrectly or not at all, it affects the overall goal only slightly. Furthermore, the omission is remedied when the telescope scans the same point in the sky.
Finally, a public-resource computing project must attract participants. There are currently enough Internet-connected computers for about 100 projects the size of SETI@home, and interesting and worthwhile projects have been proposed in areas such as global climate modeling and ecological simulation. To gain users, we believe that projects must explain and justify their goals, and must provide compelling views of local and global progress. Screensaver graphics are an excellent medium for this display, as well as providing a form of viral marketing. The success of public-resource computing projects will have the ancillary benefits of increasing public awareness of science, and democratizing, to an extent, the allocation of research resources. Acknowledgements
SETI@home was conceived by David Gedye. Woody Sullivan, Craig Kasnov, Kyle Granger, Charlie Fenton, Hiram Clawson, Peter Leiser, Eric Heien, and Steve Fulton have contributed ideas and effort to SETI@home. Thanks to our participants, and thanks to The Planetary Society, Sun Microsystems, the U.C. DiMI program, Fujifilm, Quantum, Informix, Network Appliances, and the other organizations and individuals who have supported SETI@home.
References
- COC59
- Cocconi, G., and Morrison, P., "Searching for Interstellar Communications," Nature, Vol. 184, #4690, p. 844. Sept. 1959.
- DOP90
- Declaration of Principles Concerning Activities Following the Detection of Extraterrestrial Intelligence. Acta Astronautica 21(2) pp. 153-154, 1990.
- KOR01
- Korpela, E., D. Werthimer, D. Anderson, J. Cobb, and M. Lebofsky. "SETI@home - Massively distributed computing for SETI", Computing in Science and Engineering 3(1), p. 79, 2001.
- FOS99
- Foster, I. and C. Kesselman. The Grid: Blueprint for a New Computing Infrastructure. Morgan Kauffman, 1999.
- MOL00
- Molnar, D. "The SETI@home Problem". ACM Crossroads, Sept. 2000. (http://www.acm.org/crossroads/columns/onpatrol/september2000.html)
- ORA01
- Oram, Andy (editor). Peer-to-Peer: Harnessing the Power of Disruptive Technologies. O'Reilly and Associates, 2001.
- SAR01
- Sarmenta, L. F. G. "Sabotage-Tolerance Mechanisms for Volunteer Computing Systems". ACM/IEEE International Symposium on Cluster Computing and the Grid, Brisbane, Australia, May 15-18 2001.
- SHO82
- Shoch, J. and J. Hupp. The Worm Programs -- Early Experience with a Distributed Computation". CACM 25(3) pp 172-180, March 1982.
- SHO98
- Shostak, Seth. Sharing the Universe: Perspectives on Extraterrestrial Life. Berkeley Hills Books, 1998.
- SUN90
- Sunderam, V.S. "PVM: A Framework for Parallel Distributed Programming". Concurrency: Practice and Experience, 2(4) pp. 315-339, Dec. 1990.
- WER97
- Werthimer, Bowyer, Ng, Donnelly, Cobb, Lampton and Airieau (1997). The Berkeley SETI Program: SERENDIP IV Instrumentation; in the book "Astronomical and Biochemical Origins and the Search for Life in the Universe". Cosmovici, Bowyer and Werthimer, editors.